























Искусственный интеллект

Как окружающий мир превращается в данные и почему важно знать, чему учится нейросеть во время обучения. В гостях у ведущего передачи «Вопрос науки» Алексея Семихатова кандидат физико-математических наук, доцент кафедры высшей математики Высшей школы экономики Илья Валерьевич Щуров.
Обычно данные используются для того, чтобы отвечать на какие-то вопросы про реальность. Чаще всего это переформулируется в термины, что мы хотим предсказывать значения каких-то переменных, значения каких-то величин, глядя на какие-то другие переменные, какие-то другие величины, какие-то другие параметры, которые у нас в этих данных есть. Строить как-то предсказательные модели.
Собственно говоря, этому посвящена вся дисциплина, которая раньше называлась математической статистикой и сейчас продолжает ей называться, но сейчас она получила разные другие названия и разные другие представления. Например, есть словосочетание «машинное обучение», которое во многом сводится к тому, что мы используем то, что раньше называли статистикой, но применяем к этому разные компьютерные технологии.
Машина учится как раз предсказывать значения каких-то параметров, в простейшем случае — по каким-то другим параметрам. Сначала вы скармливаете некоторому алгоритму то, что мы уже знаем, и дальше алгоритм пытается найти некоторые паттерны, некоторые взаимосвязи между разными параметрами, которые в этих данных есть, между разными переменными. Когда компьютер посмотрел на данные и смог установить какие-то закономерности в них, он может делать какие-то предсказания.
Скажем, вот есть такая сложная задачка — определить, сколько стоит тот или иной дом или объект недвижимости. И много факторов могут влиять, и нет какого-то простого закона, который бы это описывал. Но мы можем просто взять и посмотреть на рынок, посмотреть на историю сделок и про каждый дом, зафиксировать размер этого дома, когда он был построен, из какого материала он сделан, какая у него крыша… В общем, огромное количество параметров можно зафиксировать и создать такую большую табличку, где одна строчка будет соответствовать одному дому, а по столбцам будут записаны разные параметры этого дома. Наконец, поскольку мы говорим про те данные, которые у нас уже есть, мы уже знаем, за сколько этот дом был продан. И это наша обучающая выборка, которую мы можем использовать, чтобы научиться для тех домов, которые еще не были проданы, предсказывать…
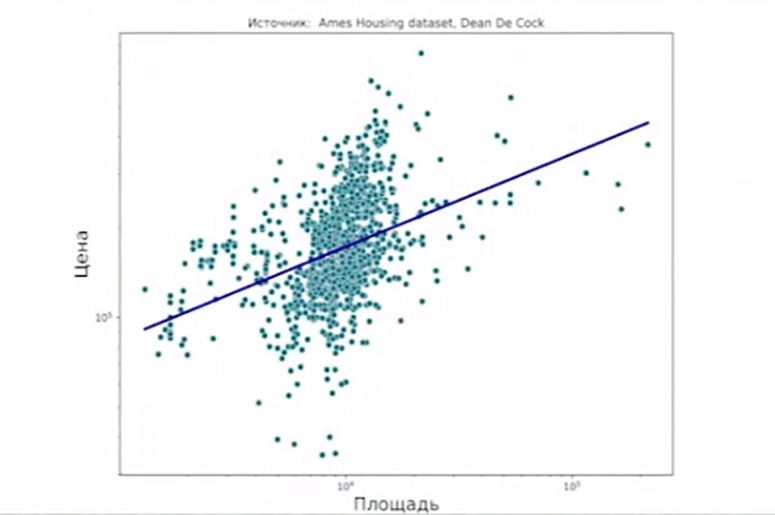
Вообще, данные бывают очень разными. Есть несколько картинок на эту тему, давайте на них посмотрим. То, что сейчас у меня нарисовано на слайде (см. рис. 1. — Прим. ред.), соответствует той самой задаче, которую мы обсуждали, — про предсказание цены жилплощади в зависимости от разных параметров. Здесь два параметра: зная только площадь, я пытаюсь предсказывать цену. Картинка показывает только связь двух величин, поэтому она такая примитивная, и, собственно говоря, то, как обычно пытаются с этими картинками работать, — это построить в качестве предсказания что-нибудь типа шкалы.
Если говорить про более сложную закономерность, то следующая по сложности модель устроена вот таким образом (см. рис. 2. — Прим. ред.). Опять же она очень простая, потому что здесь используются просто физические операции (сложение, умножение). Мы говорим, что цена определяется как сумма площади, допустим, года постройки текущего состояния, но просто с какими-то весами. Собственно, отыскание этих коэффициентов называется процедурой обучения модели. Отыскание таких коэффициентов, чтобы наша зависимость, которую мы видим в данных, хорошо описывалась формулой.

Бывают модели посложнее, и самый распространенный подход сейчас состоит в том, что мы не пытаемся написать какую-то формулу, а пытаемся построить такое дерево (см. рис. 3. — Прим. ред.). Мы про наш объект недвижимости задаем вопросы. Допустим, был ли он построен раньше 1984 года или позже. И в зависимости от ответа на эти вопросы мы делаем предсказания.
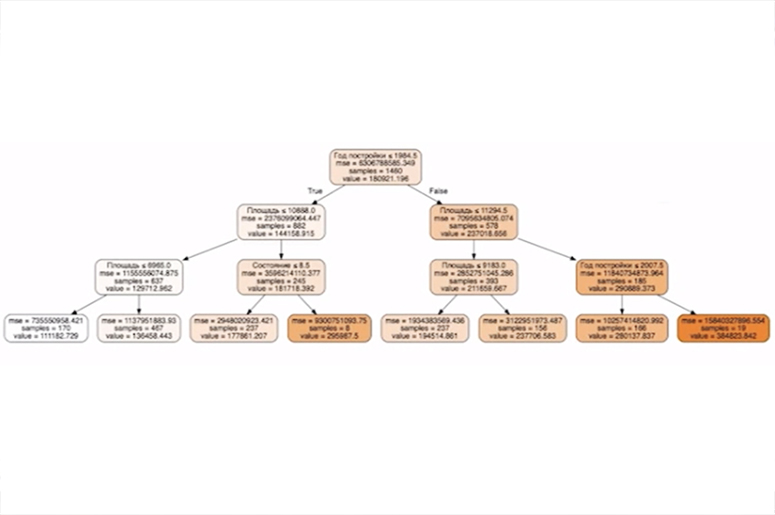
Вопросы подбирает компьютер. Это тоже часть машинного обучения — выбрать правильный вопрос, который даст вам возможность предсказывать очень хорошо. Это стандартный алгоритм решающего дерева. Если говорить про что-то более сложное, то я про картинки. Скажем, мы хотим отвечать на какие-то простые вопросы, отличать картинки, изображения, фотографии, отличать кошек от собак. Была очень сложная проблема, где-то до 2014 года не умели это делать. Сейчас появились архитектуры, основанные на сверточных нейросетях. Пример такой архитектуры — это VGG 16 (см. рис. 4. — Прим. ред.).
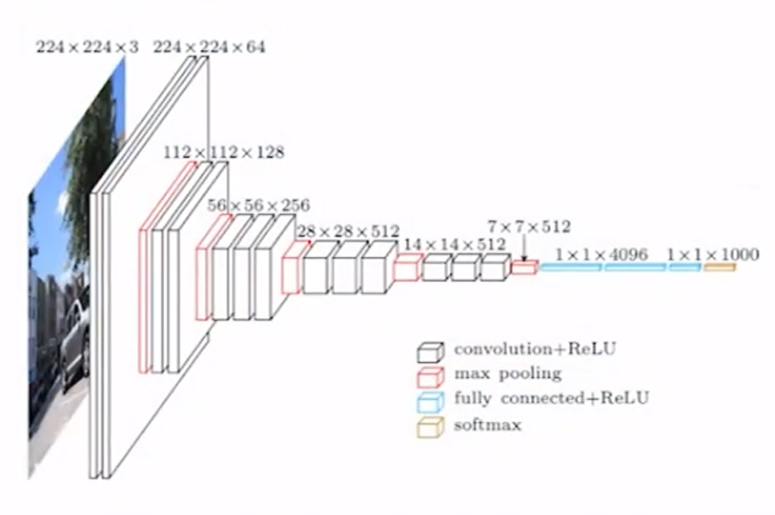
Здесь изображение подается на вход некоторой штуковине, которая дальше по слоям последовательно эти изображения обрабатывает. Первый слой эти изображения как-то преобразует, и результат этого преобразования подает на вход второму слою. Яркость и цвета пикселей — это числа, и то, что вырабатывает первый слой, — это тоже какие-то числа. Очень интересно понять, что именно такая штука видит, потому что в конечном итоге она позволяет решать много практических задач.
Первый слой такой же по размеру, как картинка, а следующие слои оказываются меньше, потому что они принимают на вход информацию с предыдущего слоя… В конечном итоге, если вы спрашиваете, кошка это или собака, ответ ваш: да или нет. Чем дальше мы идем по этой сети, тем более сложные структуры она воспринимает. На первом слое иерархии картинка состоит, грубо говоря, из черточек, а на высоком слое иерархии картинка состоит из лиц, а где-то посередине картинка состоит из носа, глаз и т. д.
Удивительный факт состоит в том, что компьютер сам обучается этой иерархии. Это на самом деле какая-то магия. В какой-то мере те модели, которые сейчас используются, вот эти сложные модели нейросети, они являются, как говорят ученые, таким «черным ящиком» — black box. Им поступает что-то на вход, а они по каким-то собственным правилам и каким-то образом — не вполне понятно, каким именно, —получают ровно то, что нам нужно. Действительно, программист или математик решают, сколько будет слоев, как они между собой будут связаны и т. д. Но это не дает прямого ответа на вопрос, как все это в точности работает.
Это правда сейчас очень большая проблема, большая дискуссия на эту тему идет. О том, как бы нам сделать алгоритм, с одной стороны, эффективным, а с другой стороны, интерпретируемым, чтобы мы могли понимать, почему они пришли к тому или иному решению. Безусловно, мы можем натренировать алгоритм на огромном количестве разнообразных видео о том, как ездят машины. Но если вы попадаете не в стандартную ситуацию, которой не было в ваших данных, как будет действовать алгоритм — никто не знает. И это действительно большая проблема, большое препятствие к тому, чтобы, например, появились нормальные автономные автомобили, о чем сейчас все мечтают, но похоже, что это откладывается на неопределенный срок.
По всей видимости, поведение индивидуального человека еще долгое время не будет поддаваться такому алгоритмическому предсказанию, потому что мы все-таки пока еще верим в то, что у нас есть какая-то свобода воли. Сможем ли мы когда-то сделать такой алгоритм, который будет за пять минут до того, как я принял какое-то решение, предсказывать, что я приму именно это решение, — я не знаю.