Alibaba представила свою самую мощную на сегодня модель ИИ

Китайский технологический гигант Alibaba разработал модель искусственного интеллекта нового поколения — по утверждению компании, мощнее аналогов и, самое главное, не требующую гигантских расходов на обучение. South China Morning Post раскрыла подробности.
В пятницу Alibaba Cloud — подразделение Alibaba по ИИ и облачным вычислениям — представило новую модель, которая, как гласит громкий анонс, знаменует собой «будущее эффективных LLM». Новинка почти в 13 раз меньше самой крупной модели компании, выпущенной всего неделей ранее.
Несмотря на компактный размер, Qwen3-Next-80B-A3B считается одной из лучших моделей Alibaba на сегодняшний день. Секрет в эффективности: модель, как утверждают разработчики, в некоторых задачах работает в 10 раз быстрее, чем предшествующая Qwen3-32B (апрельский релиз), при этом снижая стоимость обучения на 90%.
Сооснователь британского стартапа Stability AI Эмад Мостаки написал в X, что новая модель превзошла «почти любую модель прошлого года», хотя ее обучение обошлось менее чем в 500 тыс. долларов США. Для сравнения: обучение Gemini Ultra от Google (февраль 2024 года) обошлось, по данным Индекса ИИ Стэнфордского университета, примерно в 191 миллион долларов.
По данным компании Artificial Analysis, занимающейся бенчмаркингом ИИ, Qwen3-Next-80B-A3B превзошла последние версии и DeepSeek R1, и Kimi-K2 от поддерживаемого Alibaba стартапа Moonshot AI.
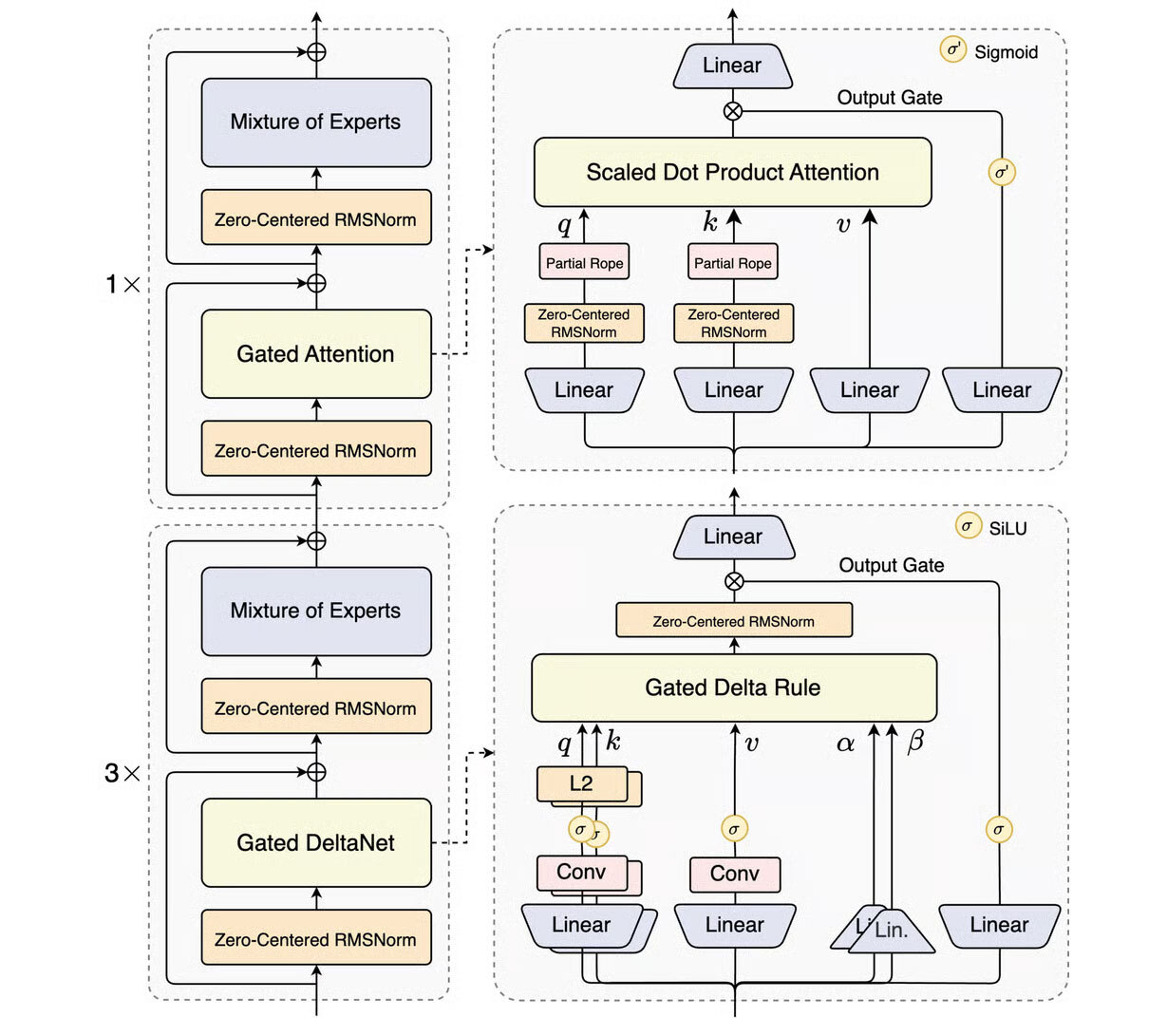
Ряд исследователей связывают успех новой модели Alibaba с относительно новой техникой под названием «гибридное внимание». У существующих моделей эффективность падает при увеличении длины входных данных из-за того, как реализован механизм «внимания». Более точное внимание требует больше вычислительных ресурсов. Это особенно дорого при работе с длинными контекстами, что делает обучение сложных ИИ-агентов крайне затратным.
Qwen3-Next-80B-A3B решает эту задачу с помощью метода Gated DeltaNet, впервые предложенного исследователями из Массачусетского технологического института и Nvidia в марте. По словам Чжоу Пэйлиня из Гонконгского университета науки и технологий, Gated DeltaNet улучшает внимание за счет выборочных корректировок входных данных и определения, какую информацию сохранить, а какую отбросить.
«Здорово видеть, что наши DeltaNet... были сильно масштабированы Alibaba для создания отличных моделей ИИ», — признался профессор Юрген Шмидхубер из Научно-технологического университета имени короля Абдаллы, внесший вклад в развитие DeltaNet еще в 1990-е.
Модель также использует архитектуру Mixture-of-Experts (MoE), обеспечившую значительный рост эффективности китайских моделей, включая DeepSeek-V3 и Kimi-K2, за последний год. MoE делит модель на несколько подсетей («экспертов»), которые специализируются на разных типах данных и совместно выполняют задачи.
Alibaba повысила «разреженность» своей MoE-архитектуры: у DeepSeek-V3 256 экспертов, а у Kimi-K2 — 384, в Qwen3-Next-80B-A3B их 512, но одновременно активируются только 10. Эти инновации позволили модели достичь уровня DeepSeek-V3.1 с всего лишь 3 миллиардами активных параметров против 37 миллиардов у конкурента.
Обычно большее количество параметров означает большую мощность, но также повышает стоимость обучения и эксплуатации. Эффективность особенно заметна на облачной платформе Alibaba: новая модель обходится дешевле в работе, чем Qwen3-235B-2507 с 235 миллиардами параметров.
Эта архитектура отражает тренд на создание более компактных и эффективных моделей на фоне озабоченности по поводу стремительного роста стоимости масштабирования крупнейших LLM. По данным исследовательской компании Epoch AI, самое дорогое на сегодня обучение Grok 4 от xAI обошлось в 490 миллионов долларов, а к 2027 году стоимость может превысить миллиард долларов.
Тем временем китайские гиганты стремятся к более широкому внедрению своих моделей, делая их достаточно компактными для запуска на ноутбуках и смартфонах. Qwen3-Next-80B-A3B получился настолько экономным к ресурсам, что его можно запустить на одном графическом процессоре Nvidia H200.
Новая архитектура — это предвестник следующего поколения моделей ИИ, уверены в Alibaba.
Скорее всего, развитие больших языковых моделей действительно пойдет по пути совершенствования метода Alibaba для сокращения издержек и роста эффективности, даже если появятся принципиально новые архитектуры, подтвердил исследователь ИИ Тобиас Шредер из Имперского колледжа Лондона.