Разработан способ обучения нейросетей на мемристорах
В Китае разработан способ обучения нейросетей на мемристорах, который может сократить энергопотребление искусственного интеллекта в миллион раз. Методику уже протестировали на реальном железе.
Аналоговые вычисления в памяти на основе мемристоров обещают преодолеть энергетические ограничения цифровых чипов, выполняя матричные операции с помощью физических законов. Мемристоры — это устройства, которые, подобно синапсам мозга, сочетают в себе функции памяти и обработки.
Как показали практические эксперименты, выдача на таких системах работает хорошо. Однако обучение глубоких нейронных сетей упирается в проблему: «шум записи» при установке весов мемристора. Это похоже на попытку поймать волну на радиоприемнике с неисправной ручкой настройки: необходимое крошечное смещение теряется в шуме из-за допусков программирования и дрейфа после записи. В результате веса меняются хаотично, вместо того чтобы точно сходиться, как требует алгоритм обратного распространения ошибки. Этот стохастический хаос дестабилизирует обучение.
Метод вероятностного обновления с учетом ошибок (EaPU), описанный в журнале Nature Communications, решает проблему, разумно пропуская большинство мелких корректировок и масштабируя остальные в соответствии с особенностями оборудования, что сокращает количество операций записи более чем на 99%.
Помехи от железа
В стандартных нейронных сетях алгоритмы обратного распространения ошибки вносят небольшие точные корректировки в веса сети во время обучения. Это работает путем расчета градиентов от функции потерь и распространения ошибок в обратном направлении слой за слоем, постепенно подстраивая «силу синапсов», чтобы минимизировать ошибки предсказания.
Мемристоры, однако, элементы непредсказуемые: сохраненные ими значения со временем дрейфуют из-за ошибок программирования и случайных флуктуаций.
«Мы наблюдали в многочисленных экспериментах, что ошибка обновления (записи) мемристоров со временем возрастает, что в основном связано с характеристиками релаксации устройства, — пояснили исследователи. — Эта проблема ухудшает стабильность и эффективность обучения. Целью нашего исследования стало устранение несоответствия между ошибкой обновления устройства и величиной обновления весов в алгоритме».
Они обнаружили, что желаемые изменения весов в нейросетях обычно в 10–100 раз меньше, чем собственный шум устройств на мемристорах. Предыдущие подходы либо жертвовали точностью ради скорости, либо потребляли чрезмерную энергию, пытаясь заставить устройства принять точные состояния, — для масштабного внедрения ни то, ни другое не пригодно.
Сотрудничество с неопределенностью
Вместо того чтобы бороться с аппаратным шумом, EaPU работает с ним. Метод использует вероятностный подход, который преобразует маленькие детерминированные изменения весов в более крупные дискретные обновления, применяемые с вычисленной вероятностью — работает это, по сути, как фильтр. В двух словах механизм выглядит простым: если изменение веса оказывается ниже порога шума, EaPU с вероятностью, пропорциональной желаемому изменению, применяет полный пороговый импульс — или пропускает обновление вовсе. Более крупные обновления проходят без изменений.
«Главная идея метода состоит в том, что величина обновления ΔW стандартного алгоритма обратного распространения преобразуется в величину обновления мемристора ΔWth с помощью вероятностного преобразования, при этом гарантируется, что среднее значение обновлений остается неизменным для сохранения эффективности обучения», — уточнили авторы.
Эффективность разработки поражает воображение. EaPU сокращает количество параметров, требующих обновления во время обучения, до менее чем 0,1%. Например, для 152-слойной нейросети ResNet на каждом шаге требовалось обновлять всего 0,86 параметра из тысячи.
Проверка на разных масштабах
Проверка подтвердила впечатляющие результаты. Исследователи обучили нейросети для устранения шумов на изображениях и повышения их разрешения, запущенные на специально построенной матрице мемристоров 180 нм. Полученные индексы структурного сходства (SSIM) составили 0,896 и 0,933 соответственно — результаты, сравнимые с традиционными методами.
Технической возможности для проверки более крупных сетей у авторов не было, и они прибегли к моделированию. Им удалось успешно обучить архитектуры ResNet глубиной до 152 слоев и современные модели Vision Transformer, добившись улучшения точности более чем на 60% по сравнению со стандартными методами обратного распространения на шумном оборудовании.
Энергетические преимущества поразительны. По сравнению с предыдущими подходами к обучению на мемристорах, EaPU сокращает энергопотребление при обучении в 50 раз, а по сравнению с передовым методом MADEM — в 13 раз. Резкое снижение частоты обновлений также продлевает срок службы оборудования приблизительно в 1000 раз.
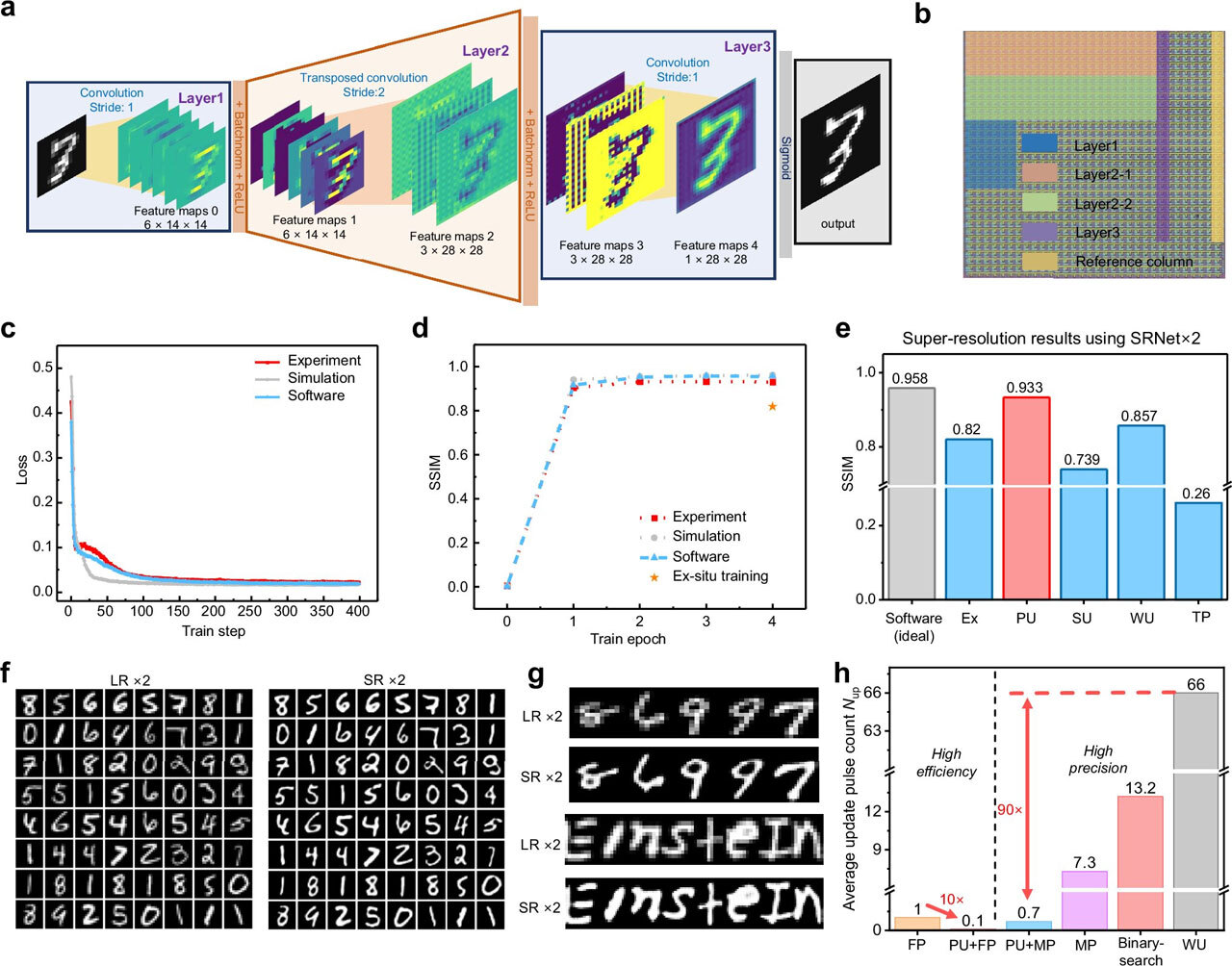
Схема сети SRNet×2 (a). Фотография мемристорного чипа, где разными цветами отмечены области, соответствующие разным слоям сети (b). Результаты работы сети — сравнение размытого и улучшенного изображения (f, g).
Что дальше
Метод найдет применение не только на железе с мемристорами, надеются разработчики. Его можно адаптировать к другим технологиям памяти, таким как ферроэлектрические транзисторы и магниторезистивая RAM.
А самое главное — EaPU может быть применен к кластерам для обучения больших языковых моделей. Модели ИИ становятся все крупнее — соответственно, растут затраты на энергию, достигая астрономических величин в миллионы долларов. И здесь упомянутый в начале выигрыш в миллион раз (по сравнению с машинами на GPU) — как нельзя кстати.